






Capturing a single moment in time is the core essence of traditional photography, yet our digital galleries are often filled with thousands of silent, motionless images that fail to convey a full story.
In a modern digital landscape where video dominates user attention, these static assets can feel insufficient for professional storytelling or personal preservation. By utilizing Image to Video AI, creators can breathe life into still frames, turning them into high-fidelity sequences that retain the original artistic intent while adding the vital dimension of time.
The difficulty of traditional video production often acts as a significant barrier for many talented individuals. Manually animating a photograph requires deep technical expertise in complex software suites that usually take years of practice to master. Modern generative technology simplifies this structural complexity, allowing anyone with a creative vision to direct a scene without requiring a camera crew or a high-end editing suite. This shift represents a democratization of motion graphics, moving away from labor-intensive frame-by-frame manipulation toward intuitive, prompt-driven generation.
Advanced Neural Models Empowering New Standards in Visual Content Creation
The technological infrastructure behind this platform is built upon a foundation of multiple high-performance neural models. Rather than relying on a single algorithm, the system integrates diverse architectures such as Sora 2, Veo 3.1, and Seedance to provide varying aesthetic results. Based on my observations, these models excel at interpreting the spatial relationships within a 2D image, successfully extrapolating depth and lighting to create a 3D-like movement that feels consistent with the original source material.
When a user provides a static image, the AI analyzes the pixels to identify subjects, foregrounds, and backgrounds. It then applies physical simulation logic to predict how those elements should interact over a short duration. For instance, in my testing, the Veo 3.1 model appears to offer a higher degree of stability in facial movements, making it particularly useful for projects involving human subjects or character-driven narratives. This capability ensures that the transition from a still photo to a moving sequence does not lose the clarity of the initial shot.
Integrating Diverse Video Models for Specific Artistic and Motion Styles
Creativity thrives on variety, and the availability of specialized models allows for targeted outcomes. Whether a project requires the cinematic sweep of a landscape or the subtle emotional nuances of a portrait, the platform provides tools tailored to these specific needs. The inclusion of models like Seedance and Sora 2 indicates a commitment to staying at the forefront of generative research, offering users access to industry-leading rendering capabilities.
Beyond general motion, the platform offers specialized modules for specific human interactions. These include dedicated functions for simulating complex movements such as dancing, hugging, or even animating old historical photographs. These pre-set effects reduce the need for highly complex prompt engineering, allowing users to achieve specific emotional beats with minimal trial and error. The ability to choose the underlying engine gives creators the flexibility to experiment with different textures and motion weights until the output matches their mental storyboard.
Mastering Camera Control for Professional Perspective and Deep Cinematic Motion
A key differentiator in professional video production is the use of intentional camera movement. Static AI generation can sometimes feel aimless, but the inclusion of precise camera controls allows users to act as virtual cinematographers. By directing the AI to perform specific maneuvers such as panning, zooming, tilting, or rotating, the resulting video gains a level of intentionality that mimics traditional film techniques.
In my experience, using a subtle zoom-in can significantly enhance the emotional impact of a portrait, drawing the viewer closer to the subject’s expression. Conversely, a wide pan can reveal the scale of a landscape that was previously hidden by the boundaries of the static frame. These controls empower the user to define the narrative flow, ensuring that the AI is not just moving pixels randomly, but is instead executing a planned visual sequence that serves a broader purpose.
A Systematic Approach to Converting Digital Images Into Dynamic Assets
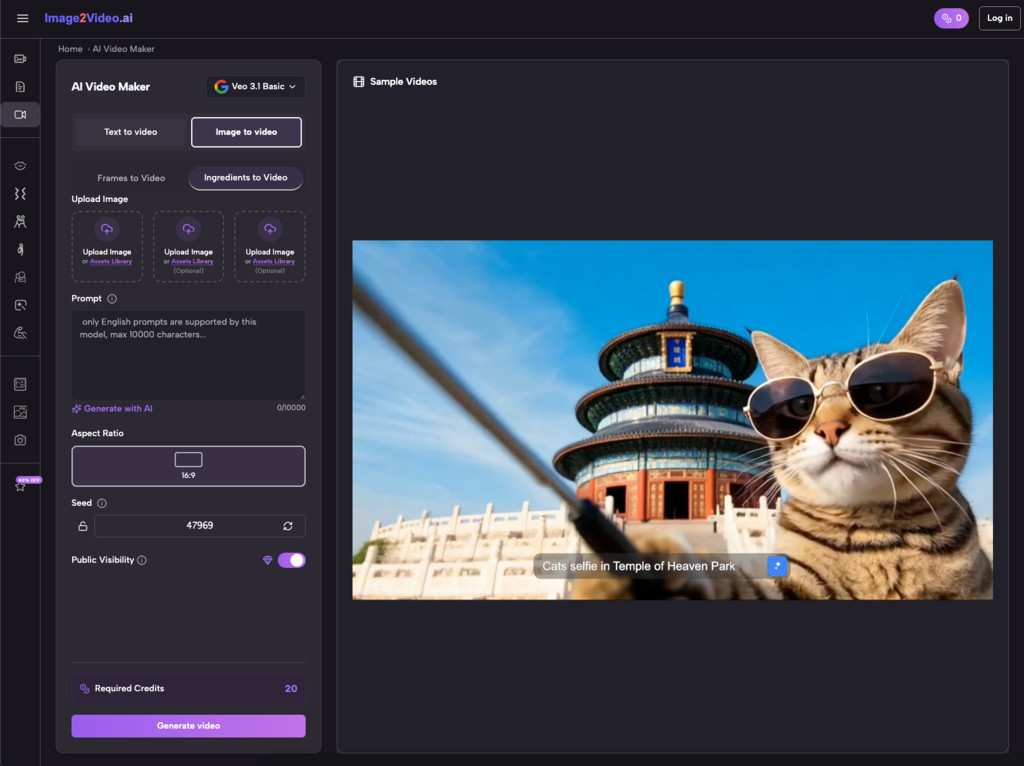
The transition from a still image to a dynamic video is governed by a streamlined four-step workflow designed to maximize efficiency for both beginners and professionals. The process is entirely web-based, removing the need for local hardware acceleration or cumbersome software installations.
- Upload Source Material: The user begins by uploading a JPEG, PNG, or JPG file. The platform is capable of processing various resolutions, though starting with a high-definition image generally yields more detailed video results.
- Define Visual Instructions: Natural language prompts are used to describe the desired motion. This can range from simple descriptions of environmental changes to complex instructions regarding subject behavior and lighting shifts.
- Execute Neural Processing: The system initiates the generation phase, which typically takes about five minutes. During this time, the AI synthesizes the frame data and applies the selected motion models to create the final 5-second sequence.
- Verify and Export: Once the status is marked as completed, the user can preview the video. The final output is provided in a universally compatible MP4 format, making it ready for immediate use in larger projects or direct sharing.
Comparing Generative Capabilities Between Standard Images and Motion Enhanced Media
To understand the value of this transformation, it is helpful to compare the attributes of static assets against those of AI-generated video. The following table highlights the functional differences in how these media formats perform across various engagement metrics.
| Performance Attribute | Static Digital Photography | AI Enhanced Motion Video |
| Narrative Depth | Limited to a single moment | Captures progression and change |
| Viewer Engagement | Low passive interaction | High active retention rates |
| Social Media Visibility | Standard algorithm reach | Prioritized by video algorithms |
| Emotional Resonance | Relies on composition only | Uses motion to build atmosphere |
| Production Complexity | Minimal effort | Streamlined AI automation |
| Delivery Format | JPEG or PNG | MP4 High Compatibility |
Real World Applications Across Marketing Education and Personal Digital Archives
The practical utility of converting images to video extends across numerous professional and personal domains. In the commercial sector, marketers are increasingly moving away from static banner ads in favor of short-form video content. A product photo that gently rotates or showcases a shimmering reflection is far more likely to capture a potential customer’s eye than a flat image.
For educators, the ability to animate diagrams or historical photos can transform a dry presentation into an immersive learning experience. Seeing a historical figure or a biological process in motion provides a level of context that text alone cannot achieve. In the personal sphere, this technology offers a way to “re-experience” memories. Animating a family photo or an old childhood snapshot adds a layer of nostalgia that feels more tangible, effectively preserving the spirit of the moment rather than just the visual data.
Boosting Engagement for E-commerce Platforms Through Automated Product Showcases
E-commerce managers face the constant challenge of making products stand out in a crowded marketplace. By utilizing automated video generation, businesses can create 360-degree views or dynamic lighting showcases from their existing catalog of high-quality photos. This not only increases the time spent on a product page but also helps in reducing the uncertainty often associated with online shopping.
In my testing of product-style prompts, the AI demonstrates a respectable ability to maintain the structural integrity of objects while adding environmental movement. This makes it an ideal solution for showcasing jewelry, tech gadgets, or fashion items where the play of light is crucial for demonstrating quality. The efficiency of the 5-minute processing time allows for the rapid creation of video content for entire product lines at a fraction of the cost of a traditional video shoot.
Revolutionizing Social Media Management With Rapid High Volume Content Turnaround
Social media managers are often required to post frequently to remain relevant, but creating original video daily is an exhausting task. The image-to-video workflow provides a shortcut to high-volume content production. By taking a single successful photo and generating several variations of motion, a manager can create a week’s worth of “Stories” or “Reels” in a single afternoon.
The ability to directly share or export these creations as MP4 files ensures that they are ready for the specific requirements of platforms like Instagram, TikTok, or Facebook. Because the platform is mobile-responsive, these updates can even be managed on the go, allowing for real-time content creation during events or launches. This agility is a significant competitive advantage in a field where speed and visual appeal are the primary currencies.
Technical Observations on Current Generative Constraints and Future Growth Potential
While the current state of Image to Video AI is remarkably advanced, it is important for professional users to understand its existing boundaries to manage expectations and refine their workflows. In my observation, the quality of the output is heavily dependent on the specificity of the input prompt. Vague instructions often lead to unpredictable motion, whereas detailed descriptions of speed, direction, and intensity yield far more professional results.
Currently, the generation length is focused on a 5-second window. While this is perfect for social media clips or B-roll in larger projects, it requires creators to think in short, impactful bursts. Additionally, very complex human movements can sometimes result in minor visual artifacts, a common trait in contemporary generative AI. Often, a second or third generation with a slightly adjusted prompt is necessary to achieve perfection. Despite these limitations, the rapid evolution of models like Seedance 2.0 suggests that the gap between AI generation and traditional cinematography is closing faster than many industry experts anticipated.
