
Normal SQLAlchemy usage leads to an ever-growing number of idle-in-transaction database connections. Here’s how to prevent them to maintain fast loading speeds.
As you work with SQLAlchemy, over time, you might have a performance nightmare brewing in the background that you aren’t even aware of.
In this lesser-known issue, which strikes primarily in larger projects, normal usage leads to an ever-growing number of idle-in-transaction database connections. These open connections can kill the overall performance of the application.
While you can fix this issue down the line, when it begins to take a toll on your performance, it takes much less work to mitigate the problem from the start.
At Gorgias, we learned this lesson the hard way. After testing different approaches, we solved the problem by extending the high-level SQLAlchemy classes (namely sessions and transactions) with functionality that allows working with “live” DB (database) objects for limited periods of time, expunging them after they are no longer needed.
This analysis covers everything you need to know to close those unnecessary open DB connections and keep your application humming along.
Leading Python web frameworks such as Django come with an integrated ORM (object-relational mapping) that handles all database access, separating most of the low-level database concerns from the actual user code. The developer can write their code focusing on the actual logic around models, rather than thinking of the DB engine, transaction management or isolation level.
While this scenario seems enticing, big frameworks like Django may not always be suitable for our projects. What happens if we want to build our own starting from a microframework (instead of a full-stack framework) and augment it only with the components that we need?
In Python, the extra packages we would use to build ourselves a full-fledged framework are fairly standard: They will most likely include Jinja2 for template rendering, Marshmallow for dealing with schemas and SQLAlchemy as ORM.
Not all projects are web applications (following a request-response pattern) and among web applications, most of them deal with background tasks that have nothing to do with requests or responses.
This is important to understand because in request-response paradigms, we usually open a DB transaction upon receiving a request and we close it when responding to it. This allows us to associate the number of concurrent DB transactions with the number of parallel HTTP requests handled. A transaction stays open for as long as a request is being processed, and that must happen relatively quickly — users don’t appreciate long loading times.
Transactions opened and closed by background tasks are a totally different story: There’s no clear and simple rule on how DB transactions are managed at a code level, there’s no easy way to tell how long tasks (should) last, and there usually isn’t any upper limit to the execution time.
This could lead to potentially long transaction times, during which the process effectively holds a DB connection open without actually using it for the majority of the time period. This state is known as an idle-in-transaction ******connection state and should be avoided as much as possible, because it blocks DB resources without actively using them.
To fully understand how database access transpires in a SQLAlchemy-based app, one needs to understand the layers responsible for the execution.
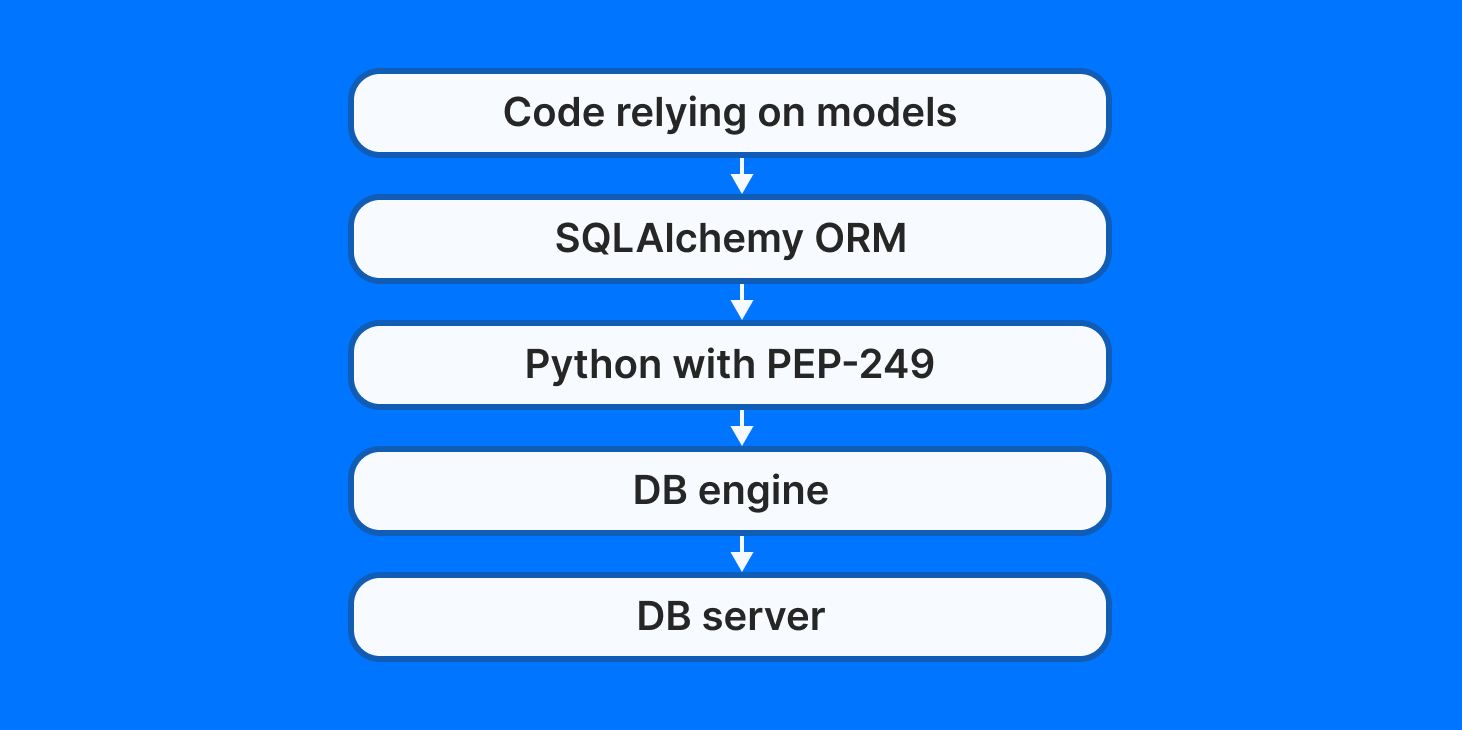
At the highest level, we code our DB interaction using high-level SQLAlchemy queries on our defined models. The query is then transformed into one or more SQL statements by SQLAlchemy’s ORM which is passed on to a database engine (driver) through a common Python DB API defined by PEP-249. (PEP-294 is a Python Enhancement Proposal dedicated to standardizing Python DB server access.) The database engine communicates with the actual database server.
At first glance, everything looks good in this stack. However there’s one tiny problem: The DB API (defined by PEP-249) does not provide an explicit way of managing transactions. In fact, it mandates the use of a default transaction regardless of the operations you’re executing, so even the simplest select will open a transaction if none are open on the current connection.
SQLAlchemy builds on top of PEP-249, doing its best to stay out of driver implementation details. That way, any Python DB driver claiming PEP-249 compatibility could work well with it.
While this is generally a good idea, SQLAlchemy has no choice but to inherit the limitations and design choices made at the PEP-249 level. More precisely (and importantly), it will automatically open a transaction for you upon the very first query, regardless whether it’s needed. And that’s the root of the issue we set out to solve: In production, you’ll probably end up with a lot of unwanted transactions, locking up on DB resources for longer than desired.
Also, SQLAlchemy uses sessions (in-memory caches of models) that rely on transactions. And the whole SQLAlchemy world is built around sessions. While you could technically ditch them to avoid the idle-in-transactions problem with a “lower-level” interface to the DB, all of the examples and documentation you’ll find online uses the “higher-level” interface (i.e. sessions). It’s likely that you will feel like you are trying to swim against the tide to get that workaround up and running.
Some DB servers, most notably Postgres, default to an autocommit ****mode. This mode implies atomicity at the SQL statement level — something developers are likely to expect. But they prefer to explicitly open a transaction block when needed and operate outside of one by default.
If you’re reading this, you have probably already Googled for “sqlalchemy autocommit” and may have found their official documentation on the (now deprecated) autocommit mode. Unfortunately this functionality is a “soft” autocommit and is implemented purely in SQLAlchemy, on top of the PEP-249 driver; it doesn’t have anything to do with DB’s native autocommit mode.
This version works by simply committing the opened transaction as soon as SQLAlchemy detects an SQL statement that modifies data. Unfortunately, that doesn’t fix our problem; the pointless, underlying DB transaction opened by non-modifying queries still remains open.
When using Postgres, we could in theory play with the new AUTOCOMMIT isolation level option introduced in psycopg2 to make use of the DB-level autocommit mode. However this is far from ideal as it would require hooking into SQLAlchemy’s transaction management and adjusting the isolation level each time as needed. Additionally, “autocommit” isn’t really an isolation level and it’s not desirable to change the connection’s isolation level all the time, from various parts of the code. You can find more details on this matter, along with a possible implementation of this idea in Carl Meyer’s article “PostgreSQL Transactions and SQLAlchemy.”
At Gorgias, we always prefer explicit solutions to implicit assumptions. By including all details, even common ones that most developers would assume by default, we can be more clear and leave less guesswork later on. This is why we didn’t want to hack together a solution behind the scenes, just to get rid of our idle-in-transactions problem. We decided to dig deeper and come up with a proper, explicit, and (almost) hack-free method to fix it.
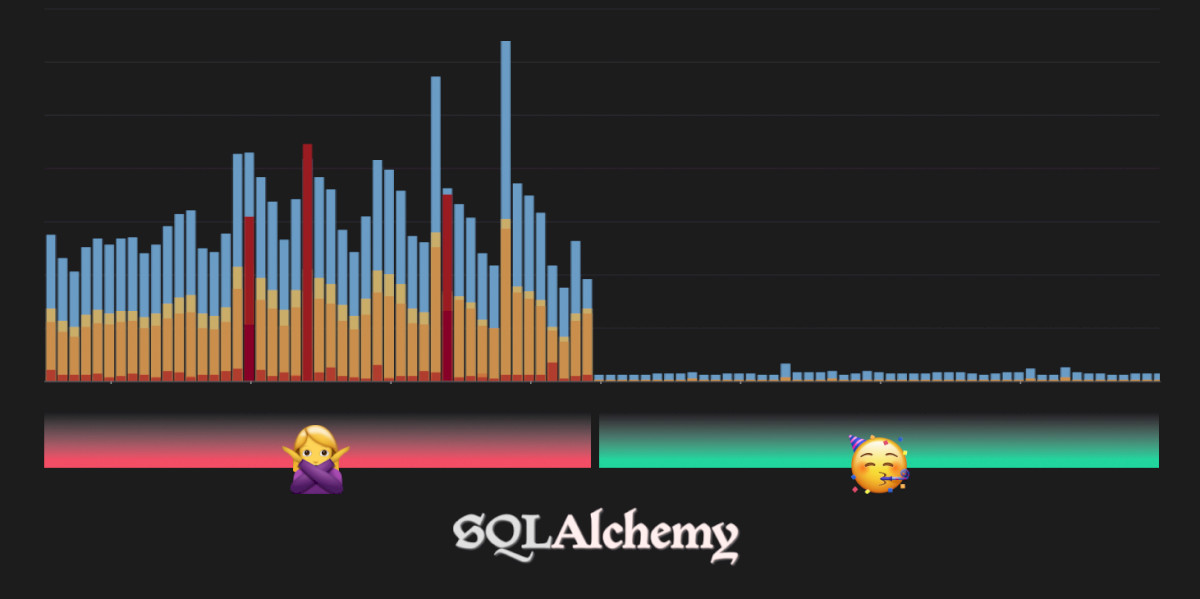
The following chart shows the profile of an idle-in-transaction case over a period of two weeks, before and after fixing the problem.
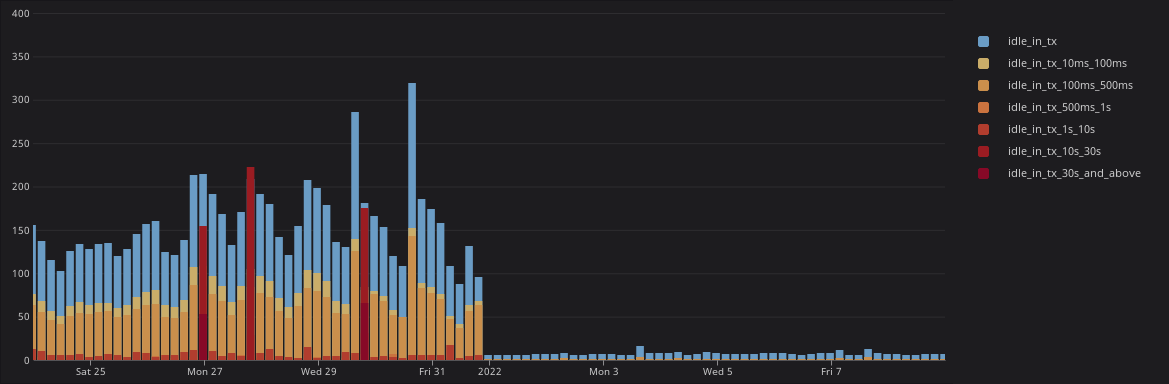
As you can see, we’re talking about tens of seconds during which connections are being held in an unusable state. In the context of a user waiting for a page to load, that is an excruciatingly long period of time.
SQLAlchemy works with sessions that are, simply put, in-memory caches of model instances. The code behind these sessions is quite complex, but usage boils down to either explicit session reference…

