

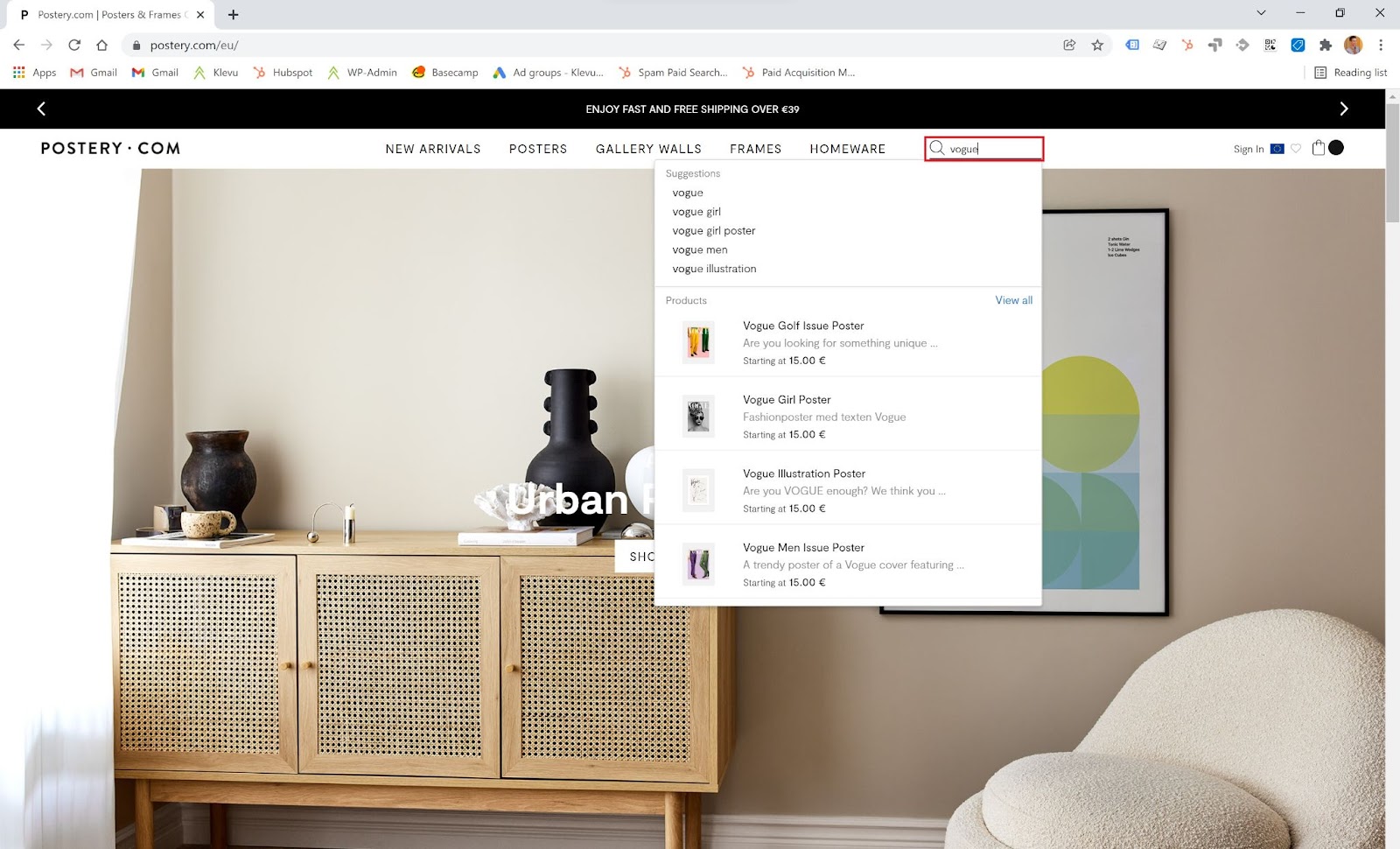
You’ve probably heard that Google doesn’t like to index site search pages. If you ask an SEO about their opinion, 90% will say you should stop indexing and crawl of the site search pages, and the source would often be a blog post Search results in search results by Matt Cutts from 2007.
But it’s not 2007. Many of Google’s guidelines have changed, and there is a growing need for technical SEO experts. One in particular, related to this subject, has vanished from Webmaster Guidelines – “Use robots.txt to prevent crawling of search results pages or other auto-generated pages that don’t add much value for users coming from search engine.”
The rationalization for why Google had that guideline back then was the poor quality of site search pages, like random and unrelated products showing up. Today that’s not the case anymore. The site search solutions have evolved – technologies like natural language processing considerably improved the quality of the site search pages.
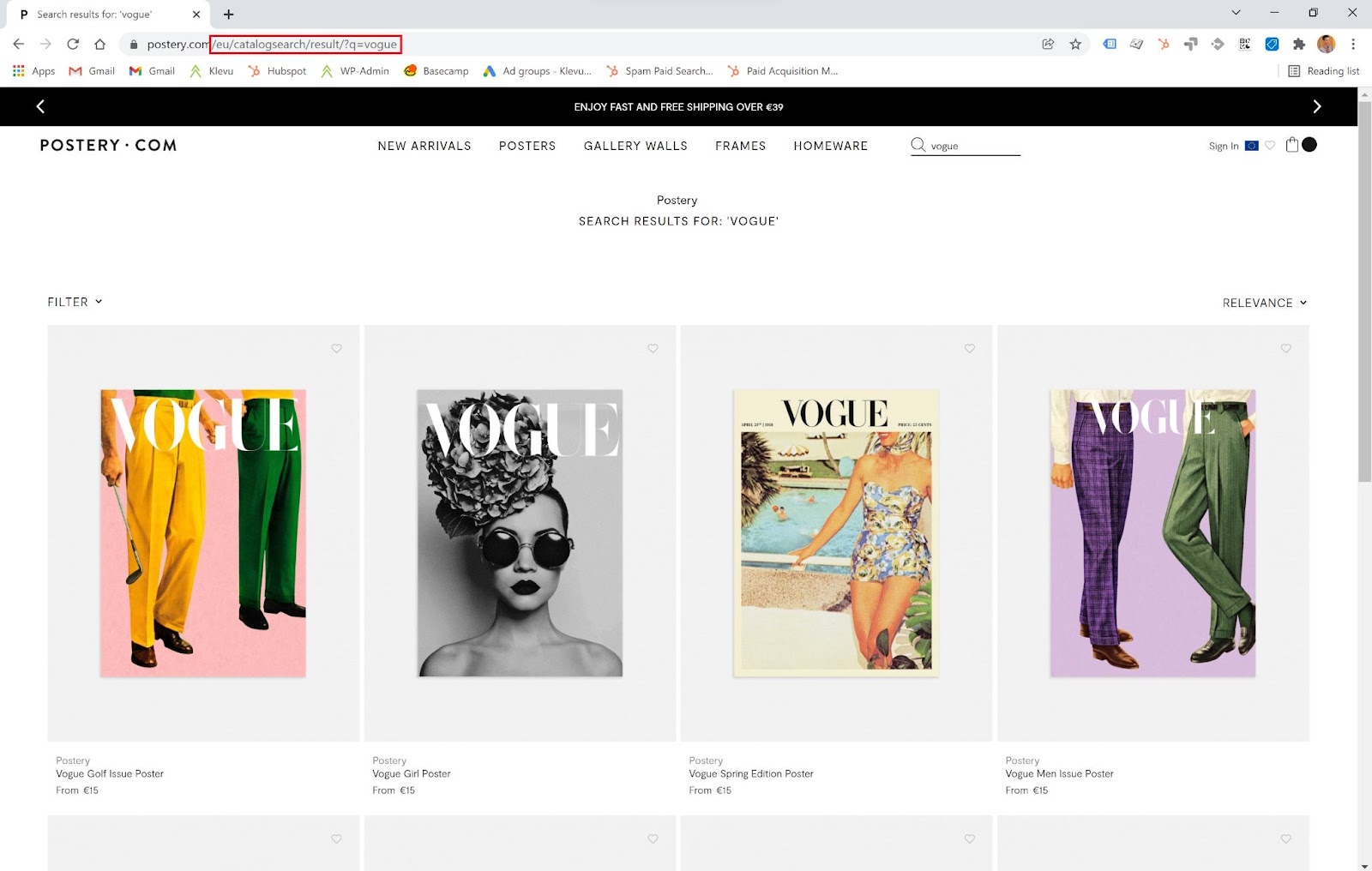
By blocking the search pages in the robots.txt file, you are not blocking the site search page indexing. Instead, you are just blocking the crawlers from reading those pages. These pages can still be indexed, as shown in the example below.

Even worse with this setup is that the links on the search pages will not be followed, so you are throwing away all external link equity from your website that could have been passed to all internal links on those pages.
Besides the bad side on the SEO front, blocking search pages in robots.txt is bad for PPC too. GoogleAds bot also follows all the rules you set, and if it is blocked via robots.txt, it can not analyze the landing page experience. And PPC experts often tend to use the site search pages for their landing pages. The consequence is lower Quality Scores and higher cost per click.
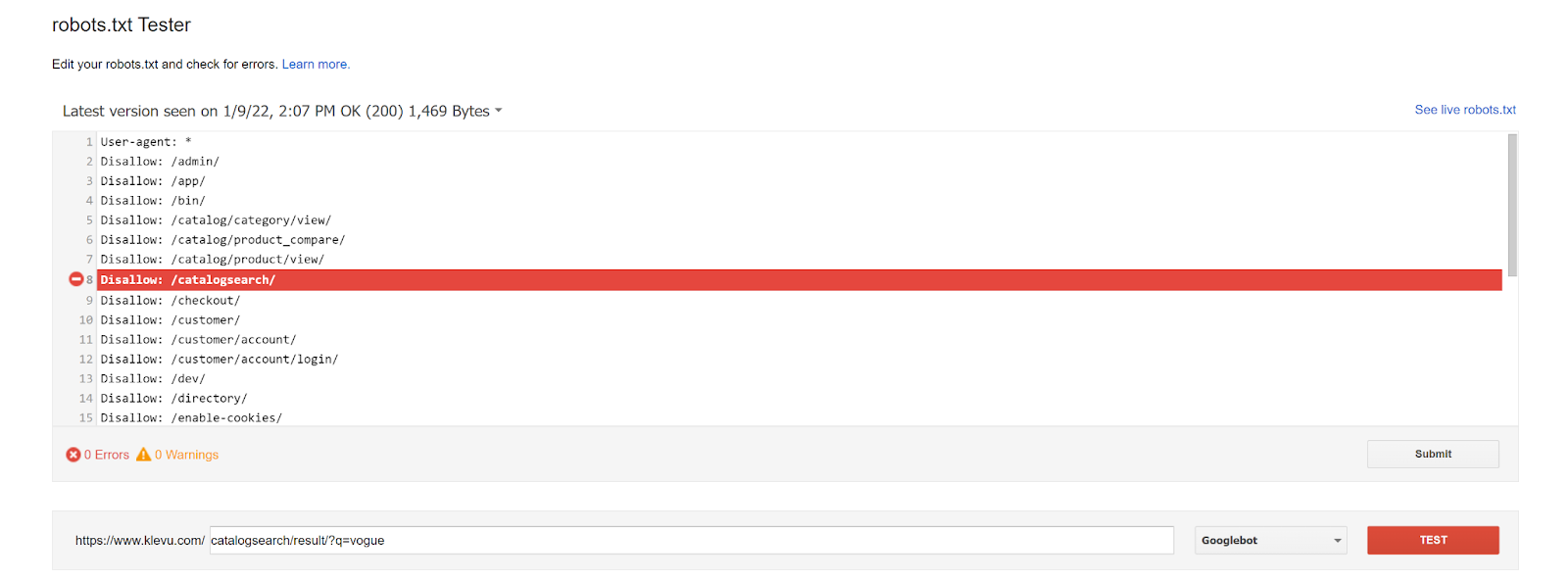
You can test if you are blocking your search pages on your website with Google’s Robots.txt Tester tool (you will need to be logged in to your Google Search Console account).
There are two types of Meta robots directives, the HTTP Header X-Robots Tag (which is sent via web server as HTTP header) and the Meta Robots Tags (a piece of HTML code on the page). They give crawlers instructions about how to crawl and index information on your pages.
HTTP Header X-Robots Tags are a rarely used method to control bots, and it’s primarily used for making sitewide crawling and indexing strategies. For example, if you want a certain type of document to be blocked for bots (let’s say you don’t want your publicly posted pdfs to be indexed). Still, you’ll want to check it out, just in case…
Using Chrome, you can open Developer Tools (Hit F12), open the Network tab, and reload the page (Hit F5). In the network name list, find and click the request URL you are on, on the right hand select the Headers, and go through your Response Headers – if you are using X-Robots-Tag it will show up here.

The Robots Meta tags are widely used to control a crawler’s behavior on the website. Robots Meta tags can be found in the document’s source – to check it out; you can right-click on the website page and click on the View page source from the dropdown menu.
In the source document, you’ll want to find the

There are a dozen different indexation controlling parameters you can use in your Meta robots directives, like NOIMAGEINDEX, NOARCHIVE, NOSNIPPET, etc., but we’ll cover only the four important ones:
You should always set your Robots Meta tag to FOLLOW on your site search pages because the site search pages are often linked to by users on social networks, websites, blogs, forums, etc… You don’t want to waste that free and organic link-building potential that is happening on your ecommerce website. If you set the parameter to NOFOLLOW, you throw all the link equity away from the site search pages.
What about the crawl budget?
That’s not something you should worry about at all. Even though there are infinite possibilities for the number of pages using the site search, crawlers will not go through your search function and start writing the queries themselves. Crawlers will just read the links they can see on your (or other) websites. If the link doesn’t exist somewhere, crawlers will not be able to reach the page.
And what about the site search indexing? Should they be indexed or not?
Some of the biggest ecommerce sites in the world are indexing their site search results – for example, Amazon and Wayfair. If you have a good site search solution that has natural language processing technology, with error tolerance, stop words, and inflections, and if you have an SEO who will do some control for potential keyword cannibalization and bad SERP control, you should go for the INDEX option. The benefits of SEO automatization through site search are far greater than its potential risks.

